In this guide, you will learn some simple Git/GitHub workflows. This includes how to create branches, create pull requests, merge branches, and switch branches. We’ll also learn a bit more about creating meaningful commits and how to fix common issues with commits.
This is aimed at people new to Git and GitHub. The focus is on GitHub.com’s visual tools and using local terminal commands.
We will walk through some sample scenarios. I would encourage you to follow along step by step.
You should already have Git installed and know what each of the following basic git commands does: git clone, add, commit, push, and pull.
If you don’t know how to use these commands, review the guide on Essential Git Commands.
Basic Workflow Example
The exact workflow you follow will vary, but let’s begin with a basic scenario.
- Suppose you are working on a small team.
- It’s just you and one other person.
- You are the person responsible for designing and coding the user interface.
- Your teammate will implement the business logic and connect the application to a database.
- To get this project done, you both must have access to the project files and be able to run the app in a local test environment.
- You’ve agreed to use Git/GitHub to maintain the codebase.
You decide to begin your project by creating a new repository. You build the boilerplate project files for the new application. The code is pushed to the new repo and your teammate is given access. There is 1 initial commit on the main branch.
In the beginning, you and your teammate are able to work independently off the first commit.
- You create the branch “interface” and begin working on the front end of your application.
- You build the user interface in the “app” folder
- Your teammate creates another branch called “library” and begins creating functions related to handling data and using the database.
- Your teammate creates their database functions in the “lib” folder.
As the week goes on, you continue working on your branch, committing and pushing changes to it regularly. Your teammate does the same with their respective branch. You’re still both working on the same project, but in different folders and on different branches.
Towards the end of the week, you decide you’ve made good progress and have finished creating the layouts and forms for the first few sections of the app. Your teammate has completed all the essential library functions needed to make those forms do things. You decide it is time to merge the two branches back together.
First, you create a pull request from your branch to the main branch. You merge your interface branch back into main and then delete your branch. Since you’re both equal collaborators on this project, you don’t need extra permission to complete the request. In most professional workflows, a senior team member would be the one reviewing and approving this.
Because the main branch hasn’t been touched since the start, and you both were working with entirely separate files, there are no conflicts. Your teammate submits a pull request on main and merges their lib branch with main. The main branch now has both your code for the user interface and their code for the database.

Now that the main branch has both developers’ code, you each can run local pull requests and get each other’s new files onto your local machines. You see how the code interacts and perhaps implement your teammate’s functions in your forms.
In most workflows, it’s best to create a new branch for each compartmentalized feature, and delete each branch after they’re merged back to the main branch.
On small teams, it may be sufficient for each developer to work on their own branch off main. On larger projects, multiple developers may be assigned to work together on a single branch. These branches can be further divided up into smaller branches. For example, the main branch might only contain production-ready code, a dev branch might be the shared branch used to develop the code, and that dev branch might be further branched off by feature.
If you’re working on a solo project, you can still use branches to help you keep track of things. This can be useful if you’re working on an experimental feature and don’t want to break your working stable codebase on the main branch.

Depending on the needs of your project, your branches can become quite complex.
Here’s a visual example of a more complex branch history. In this example, multiple features are being worked on at once, and the B branch is further divided into more branches before everything is merged back together. The dev branch is where most of the production occurs. When dev is merged with main, a new version of the app is released. Finally, between the first and second release, an error was found which needed to be fixed immediately. So a “hotfix” was made and merged back into main and dev, before the latest release.

Creating and Merging Branches
Now that you know what a basic workflow might look like, let’s learn how to create and merge branches in our own repos.
Create a new test repo with some sample files, or continue with an existing test repo. You should have a local clone and a remote GitHub repo. So either create the repo on GitHub and clone it locally or init it locally and push it to a new remote.
I’ve decided to make my test repo locally and then push it to a newly created GitHub repo.
git init git add . git commit -m "initial commit" git branch -M main git remote add origin https://your_new_repo_url.git git push -u origin main
Now that the main branch is ready, it’s time to work on a second branch.
You can see what branch you’re on at any time by typing git branch in the terminal.

Now I want to make a new “dev” branch based on the main branch before I work on anything else.
git branch dev main git branch
Now I’ve created my dev branch. However, typing “git branch” shows me I’m still on the main branch.

To quickly switch branches, use the checkout command.
git checkout dev
The branch information now shows I’m on the local dev branch.
git branch

Another, slightly quicker to create a new branch and switch to it in one step is to use the checkout command with the -b flag. This will create the new branch based on the one you’re currently on, then switch to the new one (don’t do this if you already followed the last 2 steps).
git checkout -b dev

I haven’t touched the remote repo yet. I need to update the remote (upstream) repo on GitHub.
git push -u origin dev
You should already be familiar with the git push command. However, I’ve added the -u flag along with the words origin and dev. In my previous tutorials, I only used “git push” without extra arguments because I was only dealing with 1 remote and 1 branch (main).

Since I’m pushing somewhere that’s not main, I explicitly told Git where I was trying to push to. In this scenario, the -u flag indicates that I’m pushing upstream, back to the GitHub repo I want to link to and track. The “origin” is the name of the remote repo. By default, the repo I’m connected to is named “origin”. The last argument “dev” is the branch I’m pushing to. So really, I’m just telling Git to push my files to the remote repo I’m already tracking, on the “dev” branch.
Optionally, run a git status to verify you’re on the dev branch and you’re tracking the new remote origin/dev branch.
When I view the repo on GitHub, I can see I now have two branches – main and dev. For now, they’re identical. I’m ready to use this as a starting point to add new files and features.

Next, I’ll create a few new files on my local dev branch.

Now I can create a new commit and push the files to the server. So I use the git add, commit, and push functions.
git add . git commit -m "two files created" git push
Since I’m already connected to the dev branch of the remote repo, I don’t need to type out the full “git push -u origin dev” like before. I can get away with just typing git push. However, the full command would have worked as well.

At this point I have two branches, main and dev. I’m on the dev branch, and it has 2 new files that the main branch does not have. If I look at the files in my file explorer, or in VS Code’s explorer, I see all the new files are present.

Remember, foremost Git is a file tracking and versioning tool. I can swap between copies of my local branches at any time. When I run git checkout main the files in my folder reflect this. The two new files disappear (if they do not disappear, you may need to refresh the directory with F5 key in Windows).

I can switch back to dev again, and the files reappear.
git checkout dev

Take a look at the repo on GitHub. I’ve switched to the dev branch with the dropdown.
I can see the files have been added. Additionally, it says that “This branch is 1 commit ahead of main.”
Now go to the branches page by clicking the “Branches” link just below the dropdown.

The branches page gives you an overview of all the branches in the repo. You can narrow it down by active branches, old (stale) branches, your branches, and so on. You can also create new branches directly from GitHub.
I’d like to get more info about the dev branch, so click the branch activity button towards the right.

This takes us to the branch activity page, where we can see all the commits to this branch.
Open the submenu next to the latest commit and click compare changes.

When we are on the comparing changes page, we can see the differences between two branches, or between two individual commits. In this case, it’s comparing the specifically chosen commit with the main branch.
You can use the dropdowns to compare changes between any branches.

After reviewing the files, I’ve decided I’m ready to add them to the main branch.
To do this on GitHub, I need to create a pull request. A pull request is a ticket-like request to review the changes between two repositories, resolve any conflicts, and merge them back together.
The latest change is already linked at the top in a notification. Click “compare & pull request” – this notification was likely also on the front page of your repo.

The pull request creation page allows us to see what branches we want to merge, comment on the changes, and if you scroll down, you’ll see the changed files and commit history.
In green, towards the top, it says the branches are able to merge. This means there are no conflicts between files, which can occur when multiple developers are working on the same files at once.
Create the pull request.

Once the request is created, you’ll be redirected to the new request. Here you can see your comment, review the files again, and see any of your collaborators’ comments.
If everything looks right, you can click “Merge pull request” to merge the branches. Remember that depending on the permissions given to you, you might not be able to merge things yourself. If you have senior team members, they’d likely be the ones reviewing and approving the merge. Since this is our own project, we can just finish the merge ourselves.

After confirming, the merge should be complete. You’ll see the request was closed and you can delete the branch. In most workflows, you delete the branch at this point, so do that.

Look at the commit history for the main branch of the repo. Remember, each time a merge is completed, a commit is created with the sum of the merges.

Local Merge
You can merge branches locally using the merge command. Just switch to your target branch, the branch you want to end up with, and type the “branch” command followed by the name of the branch you’re merging in. For example, if I’m on the “dev” branch and I want to merge it with the “main” branch, I would do this:
git checkout main git pull git merge dev
Note that I ran a git pull after I switched to main. You should always pull before you merge if you’re working with multiple people and intend on pushing back to the server afterwards.
git checkout main git pull git merge dev git push
Even if you do this fast, there is a chance someone else could still push something different between the time you pull, merge, and push. If that happens, the push should be rejected. You’ll have to pull again, resolve any conflicts, and then push again. This is another reason why development teams usually have a senior member in charge of reviewing things.
The HEAD
The HEAD is a reference pointing to the latest commit in your history. It’s the location of the active branch you’re working on. When you create a new commit, the HEAD is updated to point to the new commit you just created.
You can view the HEAD at any time with the command
git show head
Running this command should show you the current HEAD commit, including the details, message, and branch.

After The Merge
Many things can happen with projects between the time you first branch out your new feature and when you merge it back into the main branch.
A common scenario might involve another developer merging the changes from their branch into main after you branch out, but before you merge back in. If there are no file conflicts, the remote repository will simply have both of your changes. However, your local repository will not be up to date.

You need to make sure you run a pull request after merging the remote branches.
First, make sure you’re back on the main branch locally. Then, pull in the changes.
git checkout main git pull
Now your main branch has a copy of your changes and the other dev’s changes. You can safely start working on a new feature branch.
git checkout -b my-second-feature
And again, after you add your new changes and commit them, you push the changes to a new upstream branch.
git add . git commit -m "finished my second feature" git push -u origin my-second-feature
Finally, you rinse and repeat.
Meaningful Commits
At first, it may be difficult to determine when to commit your files. As a general rule, you should try to submit commits that are meaningful, and pertain to a single topic.
Suppose you’re editing the documentation for your project, a documentation.html file. You type up the entire document, but it’s pretty extensive. It ends up being over 1,000 lines long, broken into several different sections. How often should you commit?
In that scenario, you would probably want to commit after every major section. Perhaps even after few paragraphs, for longer sections. A single commit with the message “wrote some docs” would likely be suboptimal.
On the other hand, if you created a ton of commits, after every couple sentences, you would have created far too many commits. This will be confusing too, and your commit history will be as long as the document itself.
Ideally, you’d want to be between the two extremes. Creating descriptive commits after each paragraph. For example, something like this:
- created docs, wrote introduction, described product
- add how-to section with step-by-step graphics
- add troubleshooting details
- add support details
It’s usually a good idea to commit often. Whenever you finish coding something meaningful. This could be a short function, part of a larger function, add a couple paragraphs of documentation, etc. You might commit one file or multiple files at once, depending on the scope of your changes. In some cases, you might realize you made too many changes, and need to break the changes into several smaller commits. In other cases, you may have created too many commits and need to reduce them.
You will inevitably run into these situations. Or perhaps you just wrote a non-descriptive commit message. Thankfully, Git has several tools we can use to fix things.
Rebase
If you over-commit, you can run into a situation where you’re cluttering up your repo’s commit history. This can become problematic when you need to review what you did later on, or when your teammates try to determine what you’re working on.
Here’s an example of a cluttered commit history.

One easy way to remedy this is with the “rebase” command.
In a nutshell, rebase allows you to change your commit history. You’re taking the base of one commit and sticking it somewhere else, rewriting the commit history in the process.

While the difference between a merge and a rebase may look similar, there are some very important differences.
Foremost, when you merge branches together, you don’t fundamentally change the commit history of either branch. When you run rebase, you are rewriting the commit history by taking the commits of one branch and tacking them onto another.
Rebasing results in a linear commit history that may be easier to follow.
Because the rebase command alters commit history, it’s generally not done on shared or public branches. If you rebase your branch onto the end of the main branch, but someone else was still working off a different commit, it could result in a headache untangling everything.
To rebase one branch onto another, the command is similar to a merge:
git rebase from-branch onto-branch
So if I wanted to rebase a branch called “dev” onto my “main” branch…
git rebase dev main
Another key feature of rebase is the ability to “squash” commits together. For example, if you made a commit to introduce a new program feature, then made 2 more smaller commits shortly after to fix something, you could squish all 3 commits into one. Thus hiding the smaller commits and allowing you to only show the important commit in the commit history.
Again, you probably won’t use rebase to merge things on public repos. I like to use rebase to clean up my ugly commits and squash them into a single meaningful commit before pushing to shared remote branches.
Suppose you’re on a development branch and you want to squash your last three commits together. Currently, your commit log looks like this:
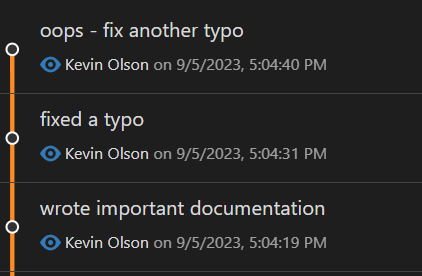
The first commit was the most important. I was writing imaginary documentation. Then, I went back and noticed some typos, so I fixed the typos on separate commits.
I would like to combine all 3 of these commits into one, with a more descriptive message of “updated site api docs”.
To do this, I can use the rebase command with the -i flag, and specifying the number of commits to get from the head (3).
git rebase -i HEAD~3
This will open some more advanced rebase features in VS Code, or whichever editor you picked to use with Git when you installed it. You can make edits directly to this file. When you save and close it, Git will finish the command.
Since I specified 3 after HEAD~ – the last 3 commits are displayed at the top of the document. It shows their SHA (secure hash algo – their ID), and the message.

Change the pick commands to squash for everything after the first. As it says below, the squash command uses the commit, but melds it into the previous. We want to meld the second and third commit into the first.
After doing this, save and close the file.

This should almost immediately open another file, where you can confirm the change and see the message.
How you want to handle your new commit message is up to you. This is the commit message which will be attached to the new combined commit. If you leave it as is, the first commit would become the new commit message, and the remaining old commit messages would be displayed when you look at the commit details.
I usually just type my new commit message at the top and save it. This will retain the previous 3 commit messages in the details, with my new commit message being the one we actually see everywhere.
If you want to use a new commit message and get rid of the old ones, just delete the contents of the whole file and type your new message. Click the little checkmark in the upper right when you’re done editing your commit message.

If everything went according to plan, you should see a message saying the rebase was successful. Now, instead of having 3 ugly commits, I have a single commit that sums up the three. I now can push this change to GitHub and merge it with other branches without worrying about judgement or making work harder on other people.